Parameter Pollution | JSON Injection
Tip
学习并实践 AWS Hacking:
HackTricks Training AWS Red Team Expert (ARTE)
学习并实践 GCP Hacking:HackTricks Training GCP Red Team Expert (GRTE)
学习并实践 Az Hacking:HackTricks Training Azure Red Team Expert (AzRTE)
支持 HackTricks
- 查看 订阅方案!
- 加入 💬 Discord 群组、telegram 群组,关注 X/Twitter 上的 @hacktricks_live,或查看 LinkedIn 页面 和 YouTube 频道。
- 通过向 HackTricks 和 HackTricks Cloud github 仓库提交 PR,分享 hacking 技巧。
HTTP Parameter Pollution (HPP) 概述
HTTP Parameter Pollution (HPP) 是一种攻击技术,攻击者通过添加、修改或复制 HTTP 参数来以非预期的方式改变 web 应用的行为。这些操纵不会直接对用户可见,但会在服务器端显著改变应用的功能,并在客户端产生可观察的影响。
HTTP Parameter Pollution (HPP) 示例
一个银行应用的交易 URL:
- 原始 URL:
https://www.victim.com/send/?from=accountA&to=accountB&amount=10000
通过插入一个额外的 from 参数:
- 被操纵的 URL:
https://www.victim.com/send/?from=accountA&to=accountB&amount=10000&from=accountC
交易可能会错误地从 accountC 扣款,而不是 accountA,这展示了 HPP 在操纵交易或其他功能(例如重置密码、2FA 设置或 API key 请求)方面的潜力。
技术特定的参数解析
- 参数的解析和优先级取决于底层的 web 技术,这会影响 HPP 的可利用方式。
- 像 Wappalyzer 这样的工具可以帮助识别这些技术及其解析行为。
PHP 与 HPP 利用
OTP 操纵案例:
- 背景: 一个需要 One-Time Password (OTP) 的登录机制被利用。
- 方法: 攻击者使用像 Burp Suite 这样的工具拦截 OTP 请求,并在 HTTP 请求中复制了
email参数。 - 结果: 本应发送到初始邮箱的 OTP,反而被发送到了被操纵请求中指定的第二个邮箱地址。该漏洞允许通过规避预期的安全措施获得未授权访问。
该场景突显了应用后端的关键疏忽:后端在生成 OTP 时处理了第一个 email 参数,但在发送时使用了最后一个。
API Key 操纵案例:
- 场景: 应用允许用户通过个人资料设置页面更新他们的 API key。
- 攻击向量: 攻击者发现,通过在 POST 请求中附加一个额外的
api_key参数,可以操纵 API key 更新函数的结果。 - 技术: 利用像 Burp Suite 这样的工具,攻击者构造了包含两个
api_key参数的请求:一个合法的和一个恶意的。服务器只处理最后一次出现的参数,因此将 API key 更新为攻击者提供的值。 - 结果: 攻击者获得了对受害者 API 功能的控制,可能未经授权访问或修改私有数据。
这个例子进一步强调了对关键功能(例如 API key 管理)进行安全参数处理的必要性。
参数解析:Flask vs. PHP
不同的 web 技术处理重复 HTTP 参数的方式不同,这影响了它们对 HPP 攻击的易受性:
- Flask: 采用遇到的第一个参数值,例如在查询字符串
a=1&a=2中优先使用a=1,而不是后来的重复值。 - PHP (在 Apache HTTP Server 上): 相反,优先使用最后一个参数值,在上述示例中选用
a=2。这种行为可能无意中助长 HPP 利用,因其会采纳攻击者操纵的参数而不是原始参数。
HPP 测试注意事项 (OWASP WSTG)
- HTTP 标准并未定义如何解释同名的多个参数,因此在不同的技术栈和组件中行为各异。
- 在测试服务器端 HPP 时,复制查询字符串或请求体中的每个参数,观察应用是否会连接值、使用第一个/最后一个,或报错。
- 对于客户端 HPP,在反射参数值中注入 URL 编码的
&(例如%26HPP_TEST),并查看生成的链接或表单 action 中是否出现解码后的&HPP_TEST或&HPP_TEST。
Server-Side Parameter Pollution (SSPP) 在内部 API 中
一些应用将用户输入嵌入到对内部 API 的服务器端请求中。如果这些输入没有正确编码,你可以在内部请求中注入或覆盖参数。测试所有用户输入,包括查询参数、表单字段、headers 和 URL 路径参数。
常见探针:
- 使用
%26(URL 编码的&)添加新参数。 - 使用
%23(URL 编码的#)截断下游查询。 - 通过复制参数覆盖已有参数。
示例:
GET /userSearch?name=peter%26name=carlos&back=/home
可能导致类似以下的服务器端请求:
GET /users/search?name=peter&name=carlos&publicProfile=true
按技术的参数污染
There results were taken from https://medium.com/@0xAwali/http-parameter-pollution-in-2024-32ec1b810f89
PHP 8.3.11 AND Apache 2.4.62
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*l_Pf2JNCYhmfAvfk7UTEbQ.jpeg
{kind=link}
- 忽略参数名中 %00 之后的任何内容。
- 将 name[] 视为数组。
- _GET 不表示 GET 方法。
- 以最后一个参数为准。
Ruby 3.3.5 and WEBrick 1.8.2
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*kKxtZ8qEmgTIMS81py5hhg.jpeg
{kind=link}
- 使用 & 和 ; 作为分隔符来拆分参数。
- 不识别 name[]。
- 以第一个参数为准。
Spring MVC 6.0.23 AND Apache Tomcat 10.1.30
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*llG22MF1gPTYZYFVCmCiVw.jpeg
{kind=link}
- POST RequestMapping == PostMapping,GET RequestMapping == GetMapping。
- POST RequestMapping 和 PostMapping 识别 name[]。
- 若同时存在 name 和 name[],则优先 name。
- 连接参数,例如 first,last。
- POST RequestMapping 和 PostMapping 在有 Content-Type 时也识别查询参数。
NodeJS 20.17.0 AND Express 4.21.0
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*JzNkLOSW7orcHXswtMHGMA.jpeg
{kind=link}
- 识别 name[]。
- 连接参数,例如 first,last。
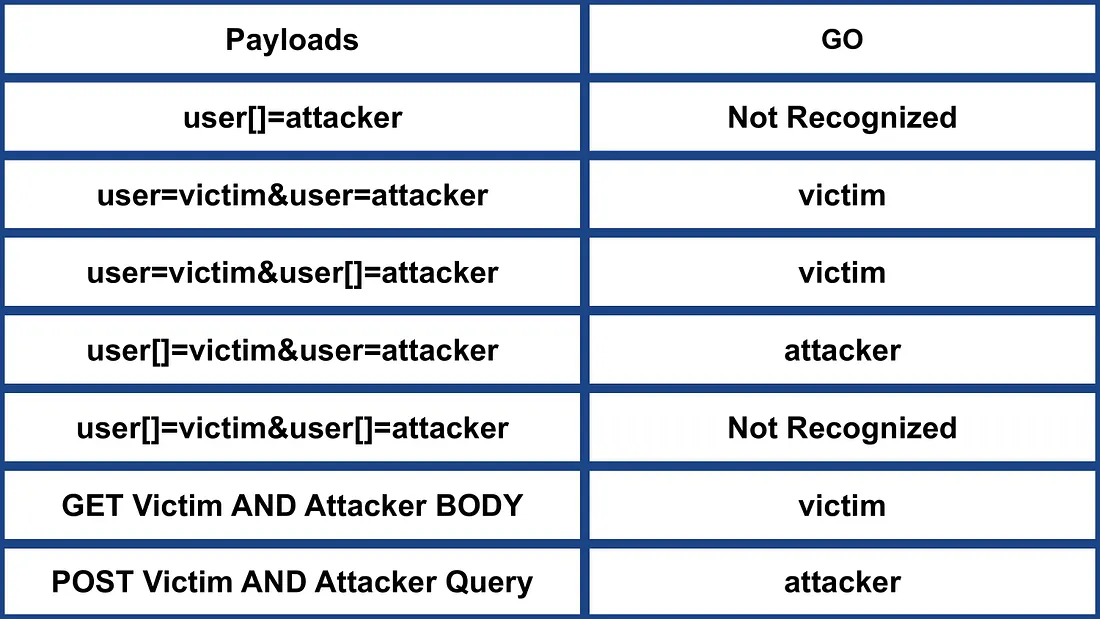
GO 1.22.7
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*NVvN1N8sL4g_Gi796FzlZA.jpeg
{kind=link}
- 不识别 name[]。
- 以第一个参数为准。
Python 3.12.6 AND Werkzeug 3.0.4 AND Flask 3.0.3
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*Se5467PFFjIlmT3O7KNlWQ.jpeg
{kind=link}
- 不识别 name[]。
- 以第一个参数为准。
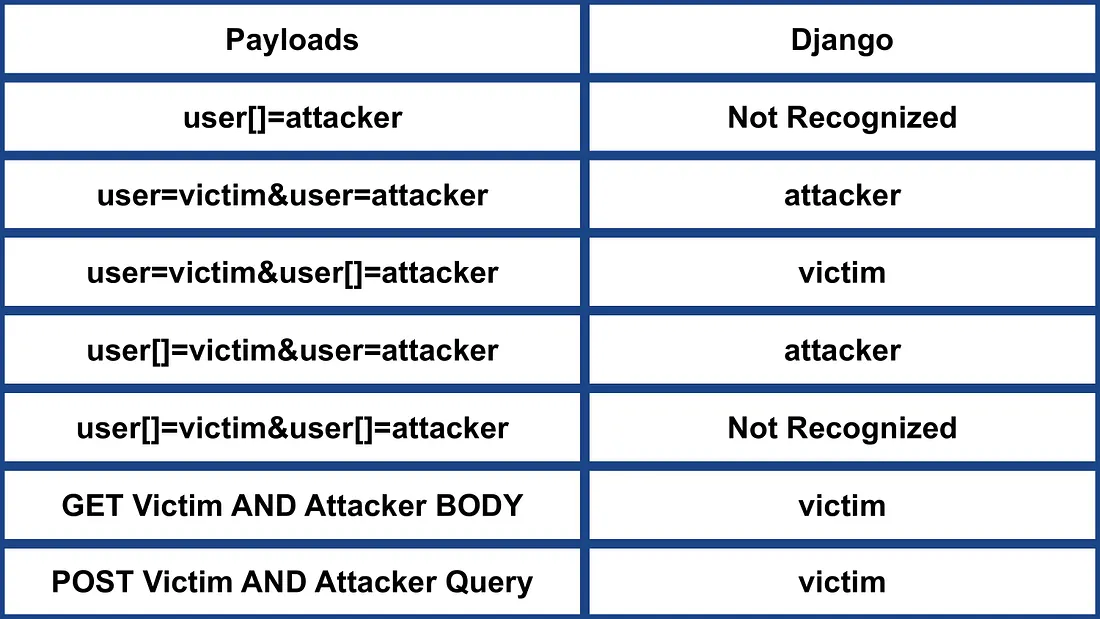
Python 3.12.6 AND Django 4.2.15
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*rf38VXut5YhAx0ZhUzgT8Q.jpeg
{kind=link}
- 不识别 name[]。
- 以最后一个参数为准。
Python 3.12.6 AND Tornado 6.4.1
.png)
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*obCn7xahDc296JZccXM2qQ.jpeg
{kind=link}
- 不识别 name[]。
- 以最后一个参数为准。
JSON Injection
Duplicate keys
obj = {"test": "user", "test": "admin"}
前端可能会相信第一个出现的键,而后端使用该键的第二次出现。
Key Collision: Character Truncation and Comments
某些字符在前端不会被正确解析,但后端会解析并使用这些键,这可以用来绕过某些限制:
{"test": 1, "test\[raw \x0d byte]": 2}
{"test": 1, "test\ud800": 2}
{"test": 1, "test"": 2}
{"test": 1, "te\st": 2}
注意在这些情况下,前端可能认为 test == 1,而后端会认为 test == 2。
这也可以用来绕过类似的值限制:
{"role": "administrator\[raw \x0d byte]"}
{"role":"administrator\ud800"}
{"role": "administrator""}
{"role": "admini\strator"}
使用 Comment Truncation
obj = {"description": "Duplicate with comments", "test": 2, "extra": /*, "test": 1, "extra2": */}
在这里我们将使用每个 parser 的 serializer 来查看其各自的输出。
Serializer 1 (e.g., GoLang’s GoJay library) will produce:
description = "Duplicate with comments"test = 2extra = ""
Serializer 2 (e.g., Java’s JSON-iterator library) will produce:
description = "Duplicate with comments"extra = "/*"extra2 = "*/"test = 1
或者,直接使用 comments 也可以有效:
obj = {"description": "Comment support", "test": 1, "extra": "a"/*, "test": 2, "extra2": "b"*/}
Java 的 GSON 库:
{ "description": "Comment support", "test": 1, "extra": "a" }
Ruby 的 simdjson 库:
{ "description": "Comment support", "test": 2, "extra": "a", "extra2": "b" }
不一致的优先级:Deserialization vs. Serialization
obj = {"test": 1, "test": 2}
obj["test"] // 1
obj.toString() // {"test": 2}
浮点数和整数
该数字
999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999
可以被解码为多种表示形式,包括:
999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999
9.999999999999999e95
1E+96
0
9223372036854775807
这可能导致不一致
参考资料
-
https://medium.com/@shahjerry33/http-parameter-pollution-its-contaminated-85edc0805654
-
https://github.com/google/google-ctf/tree/master/2023/web-under-construction/solution
-
https://medium.com/@0xAwali/http-parameter-pollution-in-2024-32ec1b810f89
-
https://bishopfox.com/blog/json-interoperability-vulnerabilities
-
https://portswigger.net/web-security/api-testing/server-side-parameter-pollution
Tip
学习并实践 AWS Hacking:
学习并实践 GCP Hacking:
学习并实践 Az Hacking:支持 HackTricks
- 查看 订阅方案!
- 加入 💬 Discord 群组、telegram 群组,关注 X/Twitter 上的 @hacktricks_live,或查看 LinkedIn 页面 和 YouTube 频道。
- 通过向 HackTricks 和 HackTricks Cloud github 仓库提交 PR,分享 hacking 技巧。